
Here is an example with a function with one input and one output, which is approximated by a neural network with one intermediate layer with 10 neurons.
Here is the J code implementing this network :
NB. Neural network universal function approximator
load 'plot'
X =: 0.1 * _40 + i. 81 NB. Input values from _4 to 4 with step 0.1
f =: 3 : '(0.5*y^3) + (y^2) + (_5*y) + 6' NB. Function to approximate
N =: 10 NB. Number of intermediate neurons
NB. Initial random values
b =: 0.1 * _100 + ? N # 200 NB. Biases
w1 =: 0.1 * _100 + ? N # 200 NB. Input weights
w2 =: 0.1 * _100 + ? N # 200 NB. Output weights
g =: (3 : '+/ w2 * 0 >. (w1 * y) + b')"0 NB. Neural approximation
loss =: +/ *: (g X) - (f X)
NB. Compute loss
NB. loss =: computeloss b, w1, w2
computeloss =: 3 : 0"_ 1
b =. (i. N) { y
w1 =. (N + i. N) { y
w2 =. ((2*N) + i. N) { y
t =. f X
p =. +/ w2 * 0 >. (w1 */ X) + b
loss =. +/ *: p - t
loss
)
eps =: 0.0001
NB. Gradient descent
descent =: 3 : 0
P =. b, w1, w2
nP =. # P
loss =. computeloss P
step =. 0
for. i. 10000 do.
step =. step + 1
loss1 =. loss
loss =. computeloss P
Pplus =: |: P + eps * (i. nP) =/ i. nP
Pminus =: |: P - eps * (i. nP) =/ i. nP
gradient =: (1%2*eps) * (computeloss Pplus) - (computeloss Pminus)
echo 'Step ', (": step), ' : loss = ', (": loss)
P =. P - 0.00001 * gradient
end.
P
)
P =: descent 0
b =: (i. N) { P
w1 =: (N + i. N) { P
w2 =: ((2*N) + i. N) { P
plot X ; (f X) ,: (g X)
pd 'pdf nnufa.pdf'
After training the network with gradient descent, it gives an approximation of the original function.
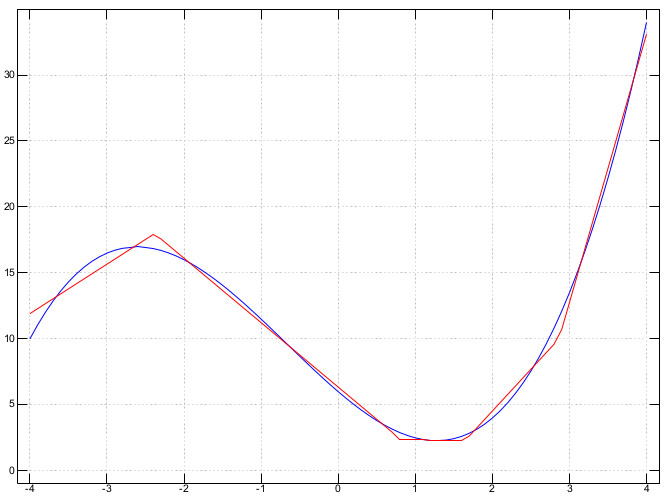
Link :