pip install opencv-python
Usage example : python object_detection.py --input object_detection.jpg --model v2 --threshold 0.9
Code :
# Object detection with PyTorch
# Source : https://debuggercafe.com/object-detection-using-pytorch-faster-rcnn-resnet50-fpn-v2/
# Usage example : python object_detection.py --input object_detection.jpg --model v2 --threshold 0.9
import torchvision.transforms as transforms
import cv2
import numpy as np
import torch
# from coco_names import COCO_INSTANCE_CATEGORY_NAMES as coco_names
coco_names = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
np.random.seed(42)
# Create different colors for each class.
COLORS = np.random.uniform(0, 255, size=(len(coco_names), 3))
# Define the torchvision image transforms.
transform = transforms.Compose([
transforms.ToTensor(),
])
def predict(image, model, device, detection_threshold):
"""
Predict the output of an image after forward pass through
the model and return the bounding boxes, class names, and
class labels.
"""
# Transform the image to tensor.
image = transform(image).to(device)
# Add a batch dimension.
image = image.unsqueeze(0)
# Get the predictions on the image.
with torch.no_grad():
outputs = model(image)
# Get score for all the predicted objects.
pred_scores = outputs[0]['scores'].detach().cpu().numpy()
# Get all the predicted bounding boxes.
pred_bboxes = outputs[0]['boxes'].detach().cpu().numpy()
# Get boxes above the threshold score.
boxes = pred_bboxes[pred_scores >= detection_threshold].astype(np.int32)
high_scores = pred_scores[pred_scores >= detection_threshold]
labels = outputs[0]['labels'][:len(boxes)]
# Get all the predicited class names.
pred_classes = [coco_names[i] for i in labels.cpu().numpy()]
print(pred_classes)
print(pred_scores[pred_scores >= detection_threshold])
return boxes, pred_classes, labels, high_scores
def draw_boxes(boxes, classes, labels, scores, image):
"""
Draws the bounding box around a detected object.
"""
lw = max(round(sum(image.shape) / 2 * 0.003), 2) # Line width.
tf = max(lw - 1, 1) # Font thickness.
for i, box in enumerate(boxes):
color = COLORS[labels[i]]
cv2.rectangle(
img=image,
pt1=(int(box[0]), int(box[1])),
pt2=(int(box[2]), int(box[3])),
color=color[::-1],
thickness=lw
)
cv2.putText(
img=image,
text=classes[i]+":"+str(round(1000*scores[i])/1000.0),
org=(int(box[0]), int(box[1]-5)),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=lw / 3,
color=color[::-1],
thickness=tf,
lineType=cv2.LINE_AA
)
return image
import torchvision
def get_model(device='cpu', model_name='v2'):
# Load the model.
if model_name == 'v2':
model = torchvision.models.detection.fasterrcnn_resnet50_fpn_v2(
weights='DEFAULT'
)
elif model_name == 'v1':
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(
weights='DEFAULT'
)
# Load the model onto the computation device.
model = model.eval().to(device)
return model
# import torch
import argparse
import cv2
# import detect_utils
# import numpy as np
from PIL import Image
# from model import get_model
# Construct the argument parser.
parser = argparse.ArgumentParser()
parser.add_argument(
'-i', '--input', default='input/image_1.jpg',
help='path to input input image'
)
parser.add_argument(
'-t', '--threshold', default=0.5, type=float,
help='detection threshold'
)
parser.add_argument(
'-m', '--model', default='v2',
help='faster rcnn resnet50 fpn or fpn v2',
choices=['v1', 'v2']
)
args = vars(parser.parse_args())
# Define the computation device.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = get_model(device, args['model'])
# Read the image.
image = Image.open(args['input']).convert('RGB')
# Create a BGR copy of the image for annotation.
image_bgr = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
# Detect outputs.
with torch.no_grad():
boxes, classes, labels, scores = predict(image, model, device, args['threshold'])
# Draw bounding boxes.
image = draw_boxes(boxes, classes, labels, scores, image_bgr)
save_name = f"{args['input'].split('/')[-1].split('.')[0]}_t{''.join(str(args['threshold']).split('.'))}_{args['model']}"
cv2.imshow('Image', image)
# cv2.imwrite(f"outputs/{save_name}.jpg", image)
cv2.imwrite(f"{save_name}.jpg", image)
cv2.waitKey(0)
|
Input image :
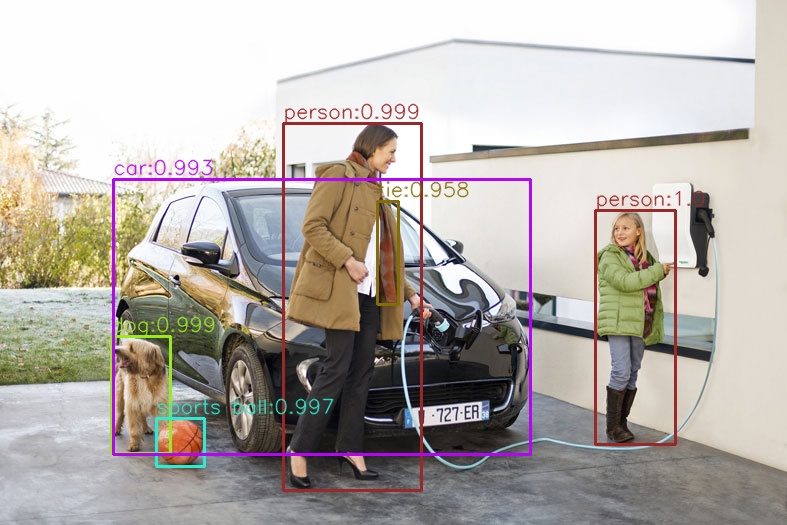
Output :