View file src/colab/copie_de_nmt_in_pytorch.py - Download
# -*- coding: utf-8 -*-
"""Copie de NMT in PyTorch.ipynb
Automatically generated by Colab.
Original file is located at
https://colab.research.google.com/drive/1en0Uxn_S0Agxw9TqYtJNLyRmxuDxyP_C
https://colab.research.google.com/drive/1uFJBO1pgsiFwCGIJwZlhUzaJ2srDbtw-
# Neural Machine Translation with Attention Using PyTorch
In this notebook we are going to perform machine translation using a deep learning based approach and attention mechanism. All the code is based on PyTorch and it was adopted from the tutorial provided on the official documentation of [TensorFlow](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb).
Specifically, we are going to train a sequence to sequence model for Spanish to English translation. If you are not familiar with sequence to sequence models, I have provided some references at the end of this tutorial to familiarize yourself with the concept. Even if you are not familiar with seq2seq models, you can still proceed with the coding exercise. I will explain tiny details that are important as we proceed.
The tutorial is very brief and I encourage you to also take a look at the official TensorFlow [notebook](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb) for more detailed explanations. The purpose of this tutorial is to understand how to convert certain code blocks into a deep learning framework like PyTorch. You will soon realize that the frameworks are very similar to some extent. The data preparation part is slightly different so I would emphasize that you spend more time analyzing this part of the code.
If you have questions you can also reach out to me at ellfae@gmail.com or Twitter ([@omarsar0](https://twitter.com/omarsar0)).
This tutorial is in a rough draft so if you find any issues with this tutorial or have any further questions reach out to me via [Twitter](https://twitter.com/omarsar0).
## Import libraries
"""
!pip3 install http://download.pytorch.org/whl/cu80/torch-0.4.1-cp36-cp36m-linux_x86_64.whl
!pip3 install torchvision
import torch
import torch.functional as F
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
import unicodedata
import re
import time
print(torch.__version__)
"""## Import Data from Google Drive
I stored the data on my Google Drive, but you can also obtain it from [here](http://www.manythings.org/anki/) as well.
"""
from google.colab import drive
drive.mount('/gdrive')
!file '/gdrive/MyDrive/DAIR RESOURCES/PyTorch/Neural Machine Translation with PyTorch/spa.txt'
f = open('/gdrive/MyDrive/DAIR RESOURCES/PyTorch/Neural Machine Translation with PyTorch/spa.txt', encoding='UTF-8', errors='ignore').read().strip().split('\n')
f
lines = f
# sample size (try with smaller sample size to reduce computation)
num_examples = 30000
# creates lists containing each pair
original_word_pairs = [[w for w in l.split('\t')[:2]] for l in lines[:num_examples]]
data = pd.DataFrame(original_word_pairs, columns=["eng", "es"])
data.head(5)
# Converts the unicode file to ascii
def unicode_to_ascii(s):
"""
Normalizes latin chars with accent to their canonical decomposition
"""
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# replacing everything with space except (a-z, A-Z, ".", "?", "!", ",")
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
w = ' ' + w + ' '
return w
"""## Data Exploration
Let's explore the dataset a bit.
"""
# Now we do the preprocessing using pandas and lambdas
data["eng"] = data.eng.apply(lambda w: preprocess_sentence(w))
data["es"] = data.es.apply(lambda w: preprocess_sentence(w))
data.sample(10)
"""## Building Vocabulary Index
The class below is useful for creating the vocabular and index mappings which will be used to convert out inputs into indexed sequences.
"""
# This class creates a word -> index mapping (e.g,. "dad" -> 5) and vice-versa
# (e.g., 5 -> "dad") for each language,
class LanguageIndex():
def __init__(self, lang):
""" lang are the list of phrases from each language"""
self.lang = lang
self.word2idx = {}
self.idx2word = {}
self.vocab = set()
self.create_index()
def create_index(self):
for phrase in self.lang:
# update with individual tokens
self.vocab.update(phrase.split(' '))
# sort the vocab
self.vocab = sorted(self.vocab)
# add a padding token with index 0
self.word2idx[''] = 0
# word to index mapping
for index, word in enumerate(self.vocab):
self.word2idx[word] = index + 1 # +1 because of pad token
# index to word mapping
for word, index in self.word2idx.items():
self.idx2word[index] = word
# index language using the class above
inp_lang = LanguageIndex(data["es"].values.tolist())
targ_lang = LanguageIndex(data["eng"].values.tolist())
# Vectorize the input and target languages
input_tensor = [[inp_lang.word2idx[s] for s in es.split(' ')] for es in data["es"].values.tolist()]
target_tensor = [[targ_lang.word2idx[s] for s in eng.split(' ')] for eng in data["eng"].values.tolist()]
input_tensor[:10]
target_tensor[:10]
def max_length(tensor):
return max(len(t) for t in tensor)
# calculate the max_length of input and output tensor
max_length_inp, max_length_tar = max_length(input_tensor), max_length(target_tensor)
def pad_sequences(x, max_len):
padded = np.zeros((max_len), dtype=np.int64)
if len(x) > max_len: padded[:] = x[:max_len]
else: padded[:len(x)] = x
return padded
# inplace padding
input_tensor = [pad_sequences(x, max_length_inp) for x in input_tensor]
target_tensor = [pad_sequences(x, max_length_tar) for x in target_tensor]
len(target_tensor)
# Creating training and validation sets using an 80-20 split
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
# Show length
len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val)
"""## Load data into DataLoader for Batching
This is just preparing the dataset so that it can be efficiently fed into the model through batches.
"""
from torch.utils.data import Dataset, DataLoader
# conver the data to tensors and pass to the Dataloader
# to create an batch iterator
class MyData(Dataset):
def __init__(self, X, y):
self.data = X
self.target = y
# TODO: convert this into torch code is possible
self.length = [ np.sum(1 - np.equal(x, 0)) for x in X]
def __getitem__(self, index):
x = self.data[index]
y = self.target[index]
x_len = self.length[index]
return x,y,x_len
def __len__(self):
return len(self.data)
"""## Parameters
Let's define the hyperparameters and other things we need for training our NMT model.
"""
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 64
N_BATCH = BUFFER_SIZE//BATCH_SIZE
embedding_dim = 256
units = 1024
vocab_inp_size = len(inp_lang.word2idx)
vocab_tar_size = len(targ_lang.word2idx)
train_dataset = MyData(input_tensor_train, target_tensor_train)
val_dataset = MyData(input_tensor_val, target_tensor_val)
dataset = DataLoader(train_dataset, batch_size = BATCH_SIZE,
drop_last=True,
shuffle=True)
class Encoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
self.gru = nn.GRU(self.embedding_dim, self.enc_units)
def forward(self, x, lens, device):
# x: batch_size, max_length
# x: batch_size, max_length, embedding_dim
x = self.embedding(x)
# x transformed = max_len X batch_size X embedding_dim
# x = x.permute(1,0,2)
x = pack_padded_sequence(x, lens) # unpad
self.hidden = self.initialize_hidden_state(device)
# output: max_length, batch_size, enc_units
# self.hidden: 1, batch_size, enc_units
output, self.hidden = self.gru(x, self.hidden) # gru returns hidden state of all timesteps as well as hidden state at last timestep
# pad the sequence to the max length in the batch
output, _ = pad_packed_sequence(output)
return output, self.hidden
def initialize_hidden_state(self, device):
return torch.zeros((1, self.batch_sz, self.enc_units)).to(device)
### sort batch function to be able to use with pad_packed_sequence
def sort_batch(X, y, lengths):
lengths, indx = lengths.sort(dim=0, descending=True)
X = X[indx]
y = y[indx]
return X.transpose(0,1), y, lengths # transpose (batch x seq) to (seq x batch)
"""## Testing the Encoder
Before proceeding with training, we should always try to test out model behavior such as the size of outputs just to make that things are going as expected. In PyTorch this can be done easily since everything comes in eager execution by default.
"""
### Testing Encoder part
# TODO: put whether GPU is available or not
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
encoder.to(device)
# obtain one sample from the data iterator
it = iter(dataset)
x, y, x_len = next(it)
# sort the batch first to be able to use with pac_pack_sequence
xs, ys, lens = sort_batch(x, y, x_len)
enc_output, enc_hidden = encoder(xs.to(device), lens, device)
print(enc_output.size()) # max_length, batch_size, enc_units
"""### Decoder
Here, we'll implement an encoder-decoder model with attention which you can read about in the TensorFlow [Neural Machine Translation (seq2seq) tutorial](https://github.com/tensorflow/nmt). This example uses a more recent set of APIs. This notebook implements the [attention equations](https://github.com/tensorflow/nmt#background-on-the-attention-mechanism) from the seq2seq tutorial. The following diagram shows that each input word is assigned a weight by the attention mechanism which is then used by the decoder to predict the next word in the sentence.
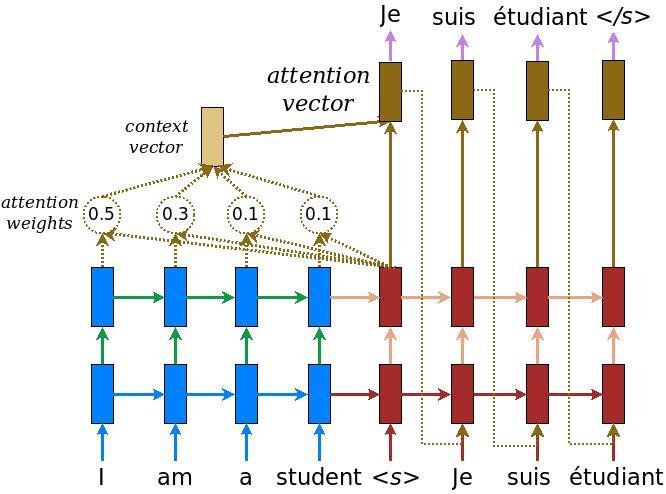 The input is put through an encoder model which gives us the encoder output of shape *(batch_size, max_length, hidden_size)* and the encoder hidden state of shape *(batch_size, hidden_size)*.
Here are the equations that are implemented:
The input is put through an encoder model which gives us the encoder output of shape *(batch_size, max_length, hidden_size)* and the encoder hidden state of shape *(batch_size, hidden_size)*.
Here are the equations that are implemented:
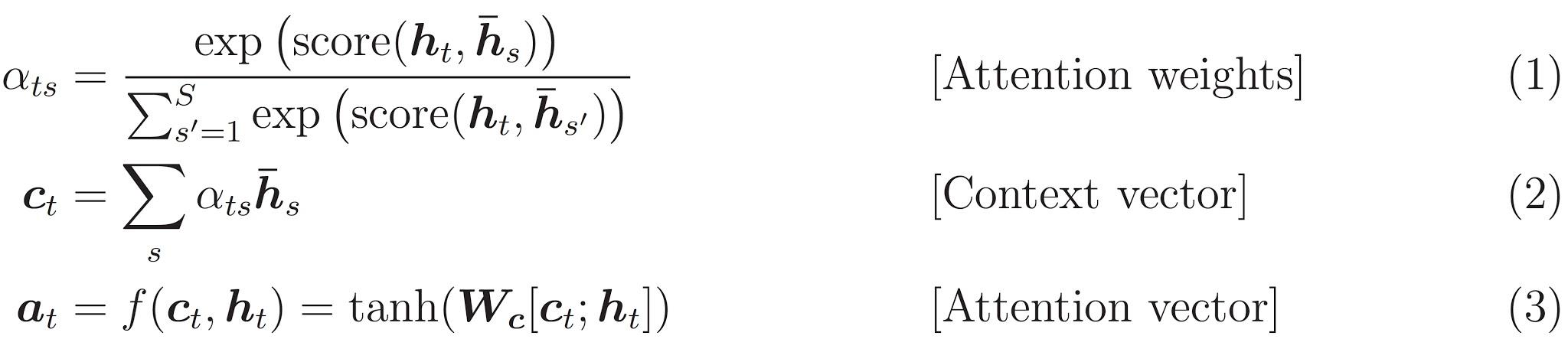
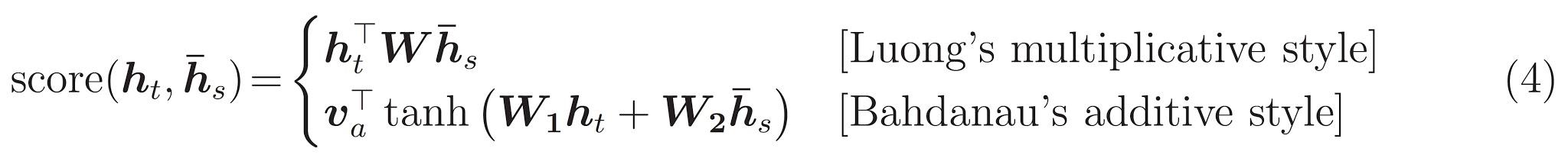 We're using *Bahdanau attention*. Lets decide on notation before writing the simplified form:
* FC = Fully connected (dense) layer
* EO = Encoder output
* H = hidden state
* X = input to the decoder
And the pseudo-code:
* `score = FC(tanh(FC(EO) + FC(H)))`
* `attention weights = softmax(score, axis = 1)`. Softmax by default is applied on the last axis but here we want to apply it on the *1st axis*, since the shape of score is *(batch_size, max_length, 1)*. `Max_length` is the length of our input. Since we are trying to assign a weight to each input, softmax should be applied on that axis.
* `context vector = sum(attention weights * EO, axis = 1)`. Same reason as above for choosing axis as 1.
* `embedding output` = The input to the decoder X is passed through an embedding layer.
* `merged vector = concat(embedding output, context vector)`
* This merged vector is then given to the GRU
The shapes of all the vectors at each step have been specified in the comments in the code:
"""
class Decoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, dec_units, enc_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.enc_units = enc_units
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
self.gru = nn.GRU(self.embedding_dim + self.enc_units,
self.dec_units,
batch_first=True)
self.fc = nn.Linear(self.enc_units, self.vocab_size)
# used for attention
self.W1 = nn.Linear(self.enc_units, self.dec_units)
self.W2 = nn.Linear(self.enc_units, self.dec_units)
self.V = nn.Linear(self.enc_units, 1)
def forward(self, x, hidden, enc_output):
# enc_output original: (max_length, batch_size, enc_units)
# enc_output converted == (batch_size, max_length, hidden_size)
enc_output = enc_output.permute(1,0,2)
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# we are doing this to perform addition to calculate the score
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
hidden_with_time_axis = hidden.permute(1, 0, 2)
# score: (batch_size, max_length, hidden_size) # Bahdanaus's
# we get 1 at the last axis because we are applying tanh(FC(EO) + FC(H)) to self.V
# It doesn't matter which FC we pick for each of the inputs
score = torch.tanh(self.W1(enc_output) + self.W2(hidden_with_time_axis))
#score = torch.tanh(self.W2(hidden_with_time_axis) + self.W1(enc_output))
# attention_weights shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
attention_weights = torch.softmax(self.V(score), dim=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * enc_output
context_vector = torch.sum(context_vector, dim=1)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
# takes case of the right portion of the model above (illustrated in red)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
#x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# ? Looks like attention vector in diagram of source
x = torch.cat((context_vector.unsqueeze(1), x), -1)
# passing the concatenated vector to the GRU
# output: (batch_size, 1, hidden_size)
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = output.view(-1, output.size(2))
# output shape == (batch_size * 1, vocab)
x = self.fc(output)
return x, state, attention_weights
def initialize_hidden_state(self):
return torch.zeros((1, self.batch_sz, self.dec_units))
"""## Testing the Decoder
Similarily, try to test the decoder.
"""
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
encoder.to(device)
# obtain one sample from the data iterator
it = iter(dataset)
x, y, x_len = next(it)
print("Input: ", x.shape)
print("Output: ", y.shape)
# sort the batch first to be able to use with pac_pack_sequence
xs, ys, lens = sort_batch(x, y, x_len)
enc_output, enc_hidden = encoder(xs.to(device), lens, device)
print("Encoder Output: ", enc_output.shape) # batch_size X max_length X enc_units
print("Encoder Hidden: ", enc_hidden.shape) # batch_size X enc_units (corresponds to the last state)
decoder = Decoder(vocab_tar_size, embedding_dim, units, units, BATCH_SIZE)
decoder = decoder.to(device)
#print(enc_hidden.squeeze(0).shape)
dec_hidden = enc_hidden#.squeeze(0)
dec_input = torch.tensor([[targ_lang.word2idx['']]] * BATCH_SIZE)
print("Decoder Input: ", dec_input.shape)
print("--------")
for t in range(1, y.size(1)):
# enc_hidden: 1, batch_size, enc_units
# output: max_length, batch_size, enc_units
predictions, dec_hidden, _ = decoder(dec_input.to(device),
dec_hidden.to(device),
enc_output.to(device))
print("Prediction: ", predictions.shape)
print("Decoder Hidden: ", dec_hidden.shape)
#loss += loss_function(y[:, t].to(device), predictions.to(device))
dec_input = y[:, t].unsqueeze(1)
print(dec_input.shape)
break
criterion = nn.CrossEntropyLoss()
def loss_function(real, pred):
""" Only consider non-zero inputs in the loss; mask needed """
#mask = 1 - np.equal(real, 0) # assign 0 to all above 0 and 1 to all 0s
#print(mask)
mask = real.ge(1).type(torch.cuda.FloatTensor)
loss_ = criterion(pred, real) * mask
return torch.mean(loss_)
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## TODO: Combine the encoder and decoder into one class
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
decoder = Decoder(vocab_tar_size, embedding_dim, units, units, BATCH_SIZE)
encoder.to(device)
decoder.to(device)
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()),
lr=0.001)
"""## Training
Now we start the training. We are only using 10 epochs but you can expand this to keep trainining the model for a longer period of time. Note that in this case we are teacher forcing during training. Find a more detailed explanation in the official TensorFlow [implementation](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb) of this notebook provided by the TensorFlow team.
- Pass the input through the encoder which return encoder output and the encoder hidden state.
- The encoder output, encoder hidden state and the decoder input (which is the start token) is passed to the decoder.
- The decoder returns the predictions and the decoder hidden state.
- The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.
- Use teacher forcing to decide the next input to the decoder.
- Teacher forcing is the technique where the target word is passed as the next input to the decoder.
- The final step is to calculate the gradients and apply it to the optimizer and backpropagate.
"""
EPOCHS = 10
for epoch in range(EPOCHS):
start = time.time()
encoder.train()
decoder.train()
total_loss = 0
for (batch, (inp, targ, inp_len)) in enumerate(dataset):
loss = 0
xs, ys, lens = sort_batch(inp, targ, inp_len)
enc_output, enc_hidden = encoder(xs.to(device), lens, device)
dec_hidden = enc_hidden
# use teacher forcing - feeding the target as the next input (via dec_input)
dec_input = torch.tensor([[targ_lang.word2idx['']]] * BATCH_SIZE)
# run code below for every timestep in the ys batch
for t in range(1, ys.size(1)):
predictions, dec_hidden, _ = decoder(dec_input.to(device),
dec_hidden.to(device),
enc_output.to(device))
loss += loss_function(ys[:, t].to(device), predictions.to(device))
#loss += loss_
dec_input = ys[:, t].unsqueeze(1)
batch_loss = (loss / int(ys.size(1)))
total_loss += batch_loss
optimizer.zero_grad()
loss.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.detach().item()))
### TODO: Save checkpoint for model
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / N_BATCH))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
"""## Final Words
Notice that we only trained the model and that's it. In fact, this notebook is in experimental phase, so there could also be some bugs or something I missed during the process of converting code or training. Please comment your concerns here or submit it as an issue in the [GitHub version](https://github.com/omarsar/pytorch_neural_machine_translation_attention) of this notebook. I will appreciate it!
We didn't evaluate the model or analyzed it. To encourage you to practice what you have learned in the notebook, I will suggest that you try to convert the TensorFlow code used in the [original notebook](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb) and complete this notebook. I believe the code should be straightforward, the hard part was already done in this notebook. If you manage to complete it, please submit a PR on the GitHub version of this notebook. I will gladly accept your PR. Thanks for reading and hope this notebook was useful. Keep tuned for notebooks like this on my Twitter ([omarsar0](https://twitter.com/omarsar0)).
## References
### Seq2Seq:
- Sutskever et al. (2014) - [Sequence to Sequence Learning with Neural Networks](Sequence to Sequence Learning with Neural Networks)
- [Sequence to sequence model: Introduction and concepts](https://towardsdatascience.com/sequence-to-sequence-model-introduction-and-concepts-44d9b41cd42d)
- [Blog on seq2seq](https://guillaumegenthial.github.io/sequence-to-sequence.html)
- [Bahdanau et al. (2016) NMT jointly learning to align and translate](https://arxiv.org/pdf/1409.0473.pdf)
- [Attention is all you need](https://arxiv.org/pdf/1706.03762.pdf)
"""
We're using *Bahdanau attention*. Lets decide on notation before writing the simplified form:
* FC = Fully connected (dense) layer
* EO = Encoder output
* H = hidden state
* X = input to the decoder
And the pseudo-code:
* `score = FC(tanh(FC(EO) + FC(H)))`
* `attention weights = softmax(score, axis = 1)`. Softmax by default is applied on the last axis but here we want to apply it on the *1st axis*, since the shape of score is *(batch_size, max_length, 1)*. `Max_length` is the length of our input. Since we are trying to assign a weight to each input, softmax should be applied on that axis.
* `context vector = sum(attention weights * EO, axis = 1)`. Same reason as above for choosing axis as 1.
* `embedding output` = The input to the decoder X is passed through an embedding layer.
* `merged vector = concat(embedding output, context vector)`
* This merged vector is then given to the GRU
The shapes of all the vectors at each step have been specified in the comments in the code:
"""
class Decoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, dec_units, enc_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.enc_units = enc_units
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
self.gru = nn.GRU(self.embedding_dim + self.enc_units,
self.dec_units,
batch_first=True)
self.fc = nn.Linear(self.enc_units, self.vocab_size)
# used for attention
self.W1 = nn.Linear(self.enc_units, self.dec_units)
self.W2 = nn.Linear(self.enc_units, self.dec_units)
self.V = nn.Linear(self.enc_units, 1)
def forward(self, x, hidden, enc_output):
# enc_output original: (max_length, batch_size, enc_units)
# enc_output converted == (batch_size, max_length, hidden_size)
enc_output = enc_output.permute(1,0,2)
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# we are doing this to perform addition to calculate the score
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
hidden_with_time_axis = hidden.permute(1, 0, 2)
# score: (batch_size, max_length, hidden_size) # Bahdanaus's
# we get 1 at the last axis because we are applying tanh(FC(EO) + FC(H)) to self.V
# It doesn't matter which FC we pick for each of the inputs
score = torch.tanh(self.W1(enc_output) + self.W2(hidden_with_time_axis))
#score = torch.tanh(self.W2(hidden_with_time_axis) + self.W1(enc_output))
# attention_weights shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
attention_weights = torch.softmax(self.V(score), dim=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * enc_output
context_vector = torch.sum(context_vector, dim=1)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
# takes case of the right portion of the model above (illustrated in red)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
#x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# ? Looks like attention vector in diagram of source
x = torch.cat((context_vector.unsqueeze(1), x), -1)
# passing the concatenated vector to the GRU
# output: (batch_size, 1, hidden_size)
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = output.view(-1, output.size(2))
# output shape == (batch_size * 1, vocab)
x = self.fc(output)
return x, state, attention_weights
def initialize_hidden_state(self):
return torch.zeros((1, self.batch_sz, self.dec_units))
"""## Testing the Decoder
Similarily, try to test the decoder.
"""
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
encoder.to(device)
# obtain one sample from the data iterator
it = iter(dataset)
x, y, x_len = next(it)
print("Input: ", x.shape)
print("Output: ", y.shape)
# sort the batch first to be able to use with pac_pack_sequence
xs, ys, lens = sort_batch(x, y, x_len)
enc_output, enc_hidden = encoder(xs.to(device), lens, device)
print("Encoder Output: ", enc_output.shape) # batch_size X max_length X enc_units
print("Encoder Hidden: ", enc_hidden.shape) # batch_size X enc_units (corresponds to the last state)
decoder = Decoder(vocab_tar_size, embedding_dim, units, units, BATCH_SIZE)
decoder = decoder.to(device)
#print(enc_hidden.squeeze(0).shape)
dec_hidden = enc_hidden#.squeeze(0)
dec_input = torch.tensor([[targ_lang.word2idx['']]] * BATCH_SIZE)
print("Decoder Input: ", dec_input.shape)
print("--------")
for t in range(1, y.size(1)):
# enc_hidden: 1, batch_size, enc_units
# output: max_length, batch_size, enc_units
predictions, dec_hidden, _ = decoder(dec_input.to(device),
dec_hidden.to(device),
enc_output.to(device))
print("Prediction: ", predictions.shape)
print("Decoder Hidden: ", dec_hidden.shape)
#loss += loss_function(y[:, t].to(device), predictions.to(device))
dec_input = y[:, t].unsqueeze(1)
print(dec_input.shape)
break
criterion = nn.CrossEntropyLoss()
def loss_function(real, pred):
""" Only consider non-zero inputs in the loss; mask needed """
#mask = 1 - np.equal(real, 0) # assign 0 to all above 0 and 1 to all 0s
#print(mask)
mask = real.ge(1).type(torch.cuda.FloatTensor)
loss_ = criterion(pred, real) * mask
return torch.mean(loss_)
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## TODO: Combine the encoder and decoder into one class
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
decoder = Decoder(vocab_tar_size, embedding_dim, units, units, BATCH_SIZE)
encoder.to(device)
decoder.to(device)
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()),
lr=0.001)
"""## Training
Now we start the training. We are only using 10 epochs but you can expand this to keep trainining the model for a longer period of time. Note that in this case we are teacher forcing during training. Find a more detailed explanation in the official TensorFlow [implementation](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb) of this notebook provided by the TensorFlow team.
- Pass the input through the encoder which return encoder output and the encoder hidden state.
- The encoder output, encoder hidden state and the decoder input (which is the start token) is passed to the decoder.
- The decoder returns the predictions and the decoder hidden state.
- The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.
- Use teacher forcing to decide the next input to the decoder.
- Teacher forcing is the technique where the target word is passed as the next input to the decoder.
- The final step is to calculate the gradients and apply it to the optimizer and backpropagate.
"""
EPOCHS = 10
for epoch in range(EPOCHS):
start = time.time()
encoder.train()
decoder.train()
total_loss = 0
for (batch, (inp, targ, inp_len)) in enumerate(dataset):
loss = 0
xs, ys, lens = sort_batch(inp, targ, inp_len)
enc_output, enc_hidden = encoder(xs.to(device), lens, device)
dec_hidden = enc_hidden
# use teacher forcing - feeding the target as the next input (via dec_input)
dec_input = torch.tensor([[targ_lang.word2idx['']]] * BATCH_SIZE)
# run code below for every timestep in the ys batch
for t in range(1, ys.size(1)):
predictions, dec_hidden, _ = decoder(dec_input.to(device),
dec_hidden.to(device),
enc_output.to(device))
loss += loss_function(ys[:, t].to(device), predictions.to(device))
#loss += loss_
dec_input = ys[:, t].unsqueeze(1)
batch_loss = (loss / int(ys.size(1)))
total_loss += batch_loss
optimizer.zero_grad()
loss.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.detach().item()))
### TODO: Save checkpoint for model
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / N_BATCH))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
"""## Final Words
Notice that we only trained the model and that's it. In fact, this notebook is in experimental phase, so there could also be some bugs or something I missed during the process of converting code or training. Please comment your concerns here or submit it as an issue in the [GitHub version](https://github.com/omarsar/pytorch_neural_machine_translation_attention) of this notebook. I will appreciate it!
We didn't evaluate the model or analyzed it. To encourage you to practice what you have learned in the notebook, I will suggest that you try to convert the TensorFlow code used in the [original notebook](https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb) and complete this notebook. I believe the code should be straightforward, the hard part was already done in this notebook. If you manage to complete it, please submit a PR on the GitHub version of this notebook. I will gladly accept your PR. Thanks for reading and hope this notebook was useful. Keep tuned for notebooks like this on my Twitter ([omarsar0](https://twitter.com/omarsar0)).
## References
### Seq2Seq:
- Sutskever et al. (2014) - [Sequence to Sequence Learning with Neural Networks](Sequence to Sequence Learning with Neural Networks)
- [Sequence to sequence model: Introduction and concepts](https://towardsdatascience.com/sequence-to-sequence-model-introduction-and-concepts-44d9b41cd42d)
- [Blog on seq2seq](https://guillaumegenthial.github.io/sequence-to-sequence.html)
- [Bahdanau et al. (2016) NMT jointly learning to align and translate](https://arxiv.org/pdf/1409.0473.pdf)
- [Attention is all you need](https://arxiv.org/pdf/1706.03762.pdf)
"""